
 linux性能分析
linux性能分析
# 影响 linux 服务器性能的因素
# CPU
描述
CPU 是操作系统稳定运行的根本,CPU 的速度与性能在很大程度上决定了系统整体的性能,因此,CPU 数量越多、主频越高,服务器性能也就相对越好。
# 内存
描述
内存的大小也是影响 Linux 性能的一个重要的因素,内存太小,系统进程将被阻塞,应用也将变得缓慢,甚至失去响应;内存太大,导致资源浪费。
# 磁盘 IO
描述
磁盘的 I/O 性能直接影响应用程序的性能,在一个有频繁读写的应用中,如果磁盘 I/O 性能得不到满足,就会导致应用停滞。好在现今的磁盘都采用了很多方法来提高 I/O 性能,比如常见的磁盘 RAID 技术。
# 网络
描述
Linux 下的各种应用,一般都是基于网络的,因此网络带宽也是影响性能的一个重要因素,低速的、不稳定的网络将导致网络应用程序的访问阻塞,而稳定、高速的网络带宽,可以保证应用程序在网络上畅通无阻地运行。幸运的是,现在的网络一般都是千兆带宽或光纤网络,带宽问题对应用程序性能造成的影响也在逐步降低。
# 常用的 linux 系统性能监控的命令
# uptime(系统整体性能评估)
 这里需要注意的是:load average 这个输出值,这三个值的大小一般不能大于系统 CPU 的个数。
这里需要注意的是:load average 这个输出值,这三个值的大小一般不能大于系统 CPU 的个数。
那么如何查看 cpu 的个数呢?
查看系统 cpu 的信息:cat /proc/cpuinfo中的信息,其中 cpu cores 即为 cpu 的核数。
也可以用 cat /proc/cpuinfo |grep "cores"|uniq 直接查看。
[root@test ~]# cat /proc/cpuinfo |grep "cores"|uniq
cpu cores : 2
2
# cpu 的性能评估
# 利用 vmstat 命令监控 cpu
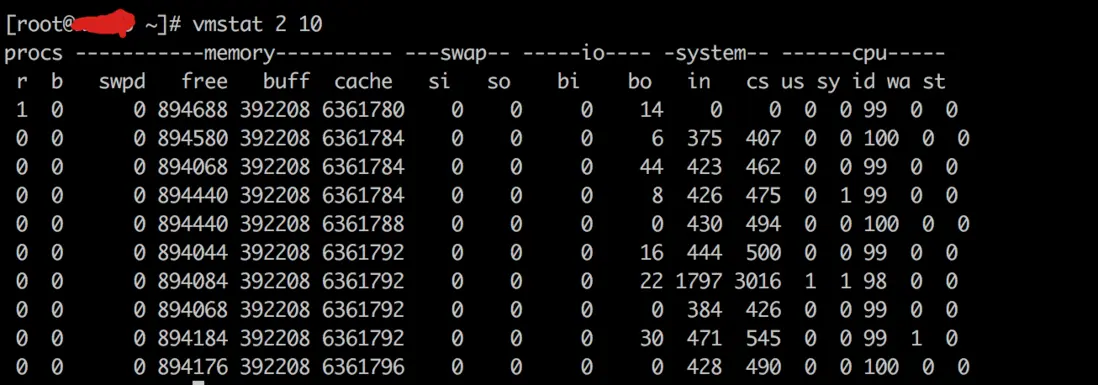
vmstat 2 10 (每 2 秒监控一次 监控 10 次)
procs
r 表示运行和等待 cpu 时间片的进程数,这个值如果长期大于 cpu 的个数,则需要增加系统 cpu。 b 表示等待资源的进程数。
CPU
us 列显示了用户进程消耗 CPU 时间百分比,us 比较高的时候,说明用户进程消耗 cpu 的时间多,如果长期大于 50%,就需要优化程序和算法。sy 列显示了内核进程消耗的 cpu 时间百分比,sy 值较高的时候,说明内核消耗的 cpu 资源很多。
根据经验,us+sy 的参考值为 80%,如果 us+sy 大于 80%说明可能存在 CPU 资源不足。
# 利用 sar 命令监控系统 cpu
sar 命令会增加系统开销 但是影响不大,yum install sysstat 安装 sar 命令
sar -u 3 5(u 显示系统所有 cpu 在采样时间内的负载状态)
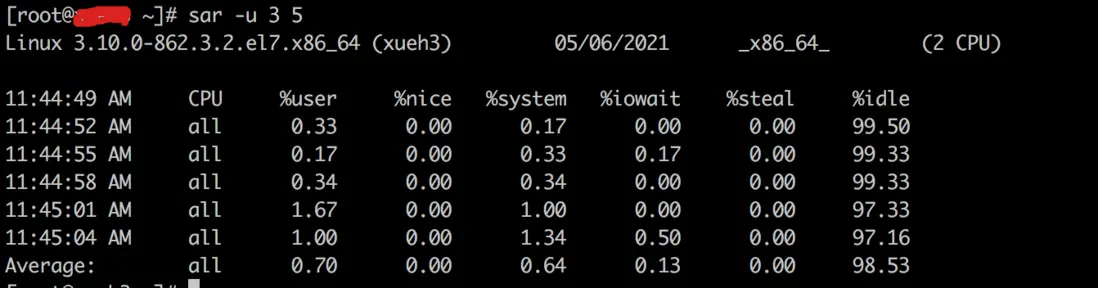
%user:用户进程消耗 cpu 的时间百分比%nice:运行正常进程所消耗 cpu 的百分比%system:系统消耗 cpu 时间百分比%iowait:IO 等待所占用 cpu 时间百分比%steal:内存在相对紧张的环境下 pagein 强制对不同页面进行的 steal 操作%idle:cpu 处在空闲时间的百分比
# 内存性能评估
# 利用 free 指令监控内存
free -m 查看以 M 为单位的内存使用情况

应用程序可用内存/系统物理内存>70%时,表示系统内存资源非常充足,不影响系统性能。
应用程序可用内存/系统物理内存<20%时,表示系统内存资源紧缺,需要增加系统内存。
20%<应用程序可用内存/系统物理内存<70%时,表示系统内存资源基本能满足应用需求,暂时不影响系统性能。
# 利用 vmstat 监控内存
swpd 表示切换到内存交换去的内存数量(k),如果 swpd 的值不为 0,或者比较大,但是 si,so 的值长期为 0,这种情况不用担心,不会影响性能。free 表示空闲的物理内存数量。buff 表示 buffers cache 的内存数量,一般对设备的读写才需要缓冲。cache 表示 page cached 的内存数量。一般作为文件系统 cached,频繁访问的文件都会被 cached,如果 cache 值较大,说明 cached 的文件较多,如果此时 IO 中的 bi 比较小,说明文件系统效率比较好。si 表示由磁盘调入内存,也就是内存进入内存交换区的数量。so 表示由内存调入磁盘,也就是内存交换区进入内存的数量。
一般情况下,so si 的值都为 0。如果 si so 的值长期不为 0,则表示系统内存不足,需要增加内存。
# 磁盘 IO 性能评估
# iostat
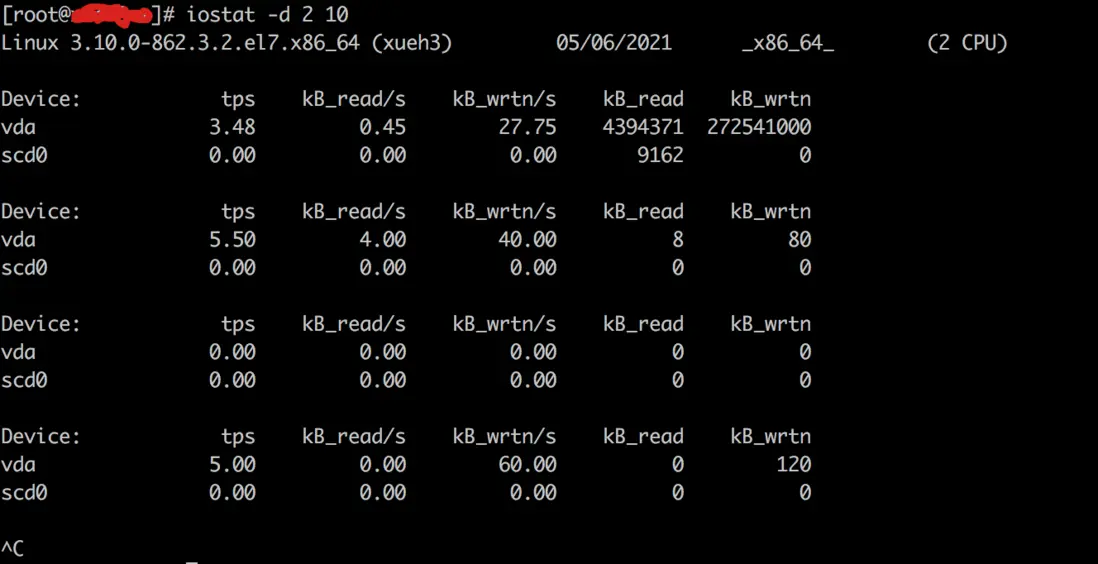
kB_reads/s 每秒读取的数据块数。kB_wrtn/s 每秒写入的数据块数。KB_read 读取的所有块数。KB_wrtn 写入的所有块数。
这几个值没有标准 如果长期都很大 肯定是不正常的。
# 利用 sar 评估磁盘性能
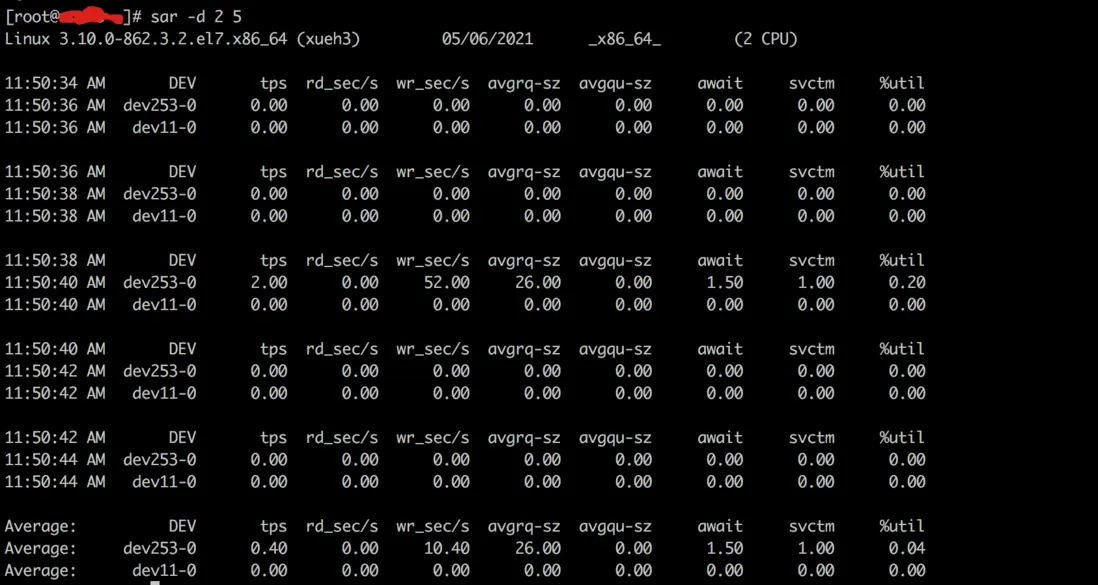
await 平均每次设备 I/O 操作的等待时间(毫秒)。svctm 平均每次设备 I/O 操作的服务时间(毫秒)。%util 一秒中有百分之几的时间用于 I/O 操作。
评判标准
正常情况下 svctm 应该是小于 await 的,svctm 的值和磁盘性能,cpu 内存等都有关系。
如果 svctm 的值和 await 的值相近表示几乎没有 I/O 等待,磁盘性能很好,如果 await 的值远高于 svctm,表示 I/O 队列等待时间太长,系统上的应用程序将变慢,此时可以通过更换更快的硬盘来解决问题。
%util 越小越好,如果%util 接近 100%表示磁盘产生的 I/O 请求太多,I/O 系统已经满负载在工作,此时可以通过优化程序或者更换更快的磁盘来解决问题。
# 网络性能评估
通过 ping 命令检测网络的连通性。
通过 netstat -i 组合检测网络接口状况。
通过 netstat -r 组合检测系统路由表信息。
通过 sar -n 组合显示系统的网络运行状态(sar -n DEV 5 3)。
查看 tcp 连接数最多的 ip:
sudo netstat -pant | grep ":22" | awk '{print $5}' | awk -F":" '{print $4}' |sort|uniq -c|sort -nr
命令解释
awk -F":" '{print $4}' 表示把结果的第 4 列用:号分割
sort -nr 排序,-n 以数值大小排序,-r 倒序,从大到小。
uniq -c 删除重复的行,-c 表示加上每行出现的次数。
netstat 命令是一个监控 TCP/IP 网络的非常有用的工具,它可以显示路由表、实际的网络连接以及每一个网络接口设备的状态信息。
netstat -pant
-p :显示正在使用 Socket 的程序识别码和程序名称;
-a :显示所有连线中的 Socket;
-n :直接使用 ip 地址,而不通过域名服务器;
-t :显示 TCP 传输协议的连线状况。
提取访问 nginx 服务器最多的 10 个 ip:
cat access.log | awk '{print $1}' | sort | uniq -c | sort -nr | head -n10